
It’s difficult to overestimate the importance of big data in today’s business environment. Companies around the globe use big data to improve customer service, optimize efficiency, and make marketing and sales more personalized and data-driven.
To get value from big data, a company needs to know how to build scalable and efficient data pipelines. In this case study, we’re sharing the Intelliarts experience of creating a data pipeline from scratch, with all its ups and downs, petty nuances, and moments your company might not have foreseen before opting into a data project.
When you start with big data analytics, data science for business, or machine learning (ML), at least half of the effort goes to data collection, storage, processing, and delivery. To put it otherwise, a big data pipeline is what puts it all together and defines the long-term success of your data project. And that’s why it’s insightful to discover the hands-on experience of building data pipelines. Additionally, employing AI data extraction techniques can significantly streamline the process of gathering and analyzing vast amounts of information.
What is a data pipeline?

A company can unleash the value of big data only if it transforms the data into actionable insights, and this insight is promptly delivered. Data silos make little sense because they cannot provide an organization with critical business insights. Even if the company manages to extract data from various sources and merge it into an Excel sheet for analysis, we guarantee errors like data redundancy are unavoidable. And imagine how much time the company would spend on manual big data analysis.
Read Also: Data Analysis in Automative Industry
By consolidating and moving data from disparate sources into one common destination, data pipelines make it possible to quickly analyze data, get business insights from it, and make informed decisions based on it. Pipelines also play an important role in your data project because they ensure consistent data quality, which is a must for reliable business insights.
In short, data pipelines are useful for businesses in:
-
Keeping data organized, normalized, and in one target location — this would definitely streamline business processes
-
Building successful business analytics and efficient BI solutions
-
Saving up time for your team — no manual data analysis and double-check of the information in the hundredth time
-
Managing data automatically and efficiently
-
Storing data securely and complying with all privacy regulations
Now when we understand why we need to build a big data pipeline, let’s discuss how to do it.
DDMR data pipeline case study
Company overview
DDMR is a US-based data-driven market research company that acts as a provider of clickstream data. Its end-users include all sorts of data analytics companies, from investment companies to hedge funds, media platforms, and marketing businesses. Our partner sells data to other organizations so its end-users would get a better understanding of their business and customers’ demands, which helps them maximize the chance of successful sales.
Business challenge
Since DDMR works with data closely (clickstream data is actually its core product), managing and processing big data is their biggest headache on the project, as well as their major business challenge.
Originally, the company reached out to Intelliarts with the request to optimize the efficiency of their data collection process. As soon as this problem was solved, DDMR wanted to generalize the solution we’ve built until they expanded their request to solve other big data challenges, such as those related to data transformation, data storage, or security.
During our cooperation, we have developed an end-to-end data pipeline, which includes data collection, storage, processing, and delivery.
The Intelliarts team has also managed to build so trusting relationship with the customer that the DDMR leadership decided to delegate all technical aspects of the project to us. Meanwhile, the customer’s team has got more time and resources to focus on business opportunities.
Solution
Through the years of partnership with DDMR, Intelliarts has built an efficient and scalable big data solution, which helped the customer manage data from the moment of data collection to delivery. Below, we discuss how the end-to-end data pipeline was built and optimized over these years of cooperation.
Data collection
As said, DDMR first contacted us to develop a browser application that could help them collect data on Firefox. As the company was selling clickstream data, the success of the entire sales department depended on its data collection method.

As soon as the application was ready, we saw the limitation of the existing data collection tool, which wasn’t technology-agnostic enough and didn’t perform well for other browsers. The logical step was to generalize the solution we’ve built and expand its use for other browsers.
On the way out, we received a platform-agnostic data collection tool with browsers as a data source (yet, it’s possible to build a similar solution for other data sources, such as a third-party system or data brokers).
Besides, data collection usually brings challenges related to users’ private and sensitive data. So, in order to respect users’ rights and not violate the rules, we’ve taken action to restrict the collection of such data.
Data storage
Significant improvements were made to the data storage process. Originally, we collected data, read, processed, and delivered it. There wasn’t any division between cold and hot data storage when we delivered data, and this was the Intelliarts team that offered to introduce it. With this change, DDMR got a chance to:
-
Access the necessary data easy and without delays via hot storage
-
Save costs on storing the data that the company rarely needs access to in cold storage
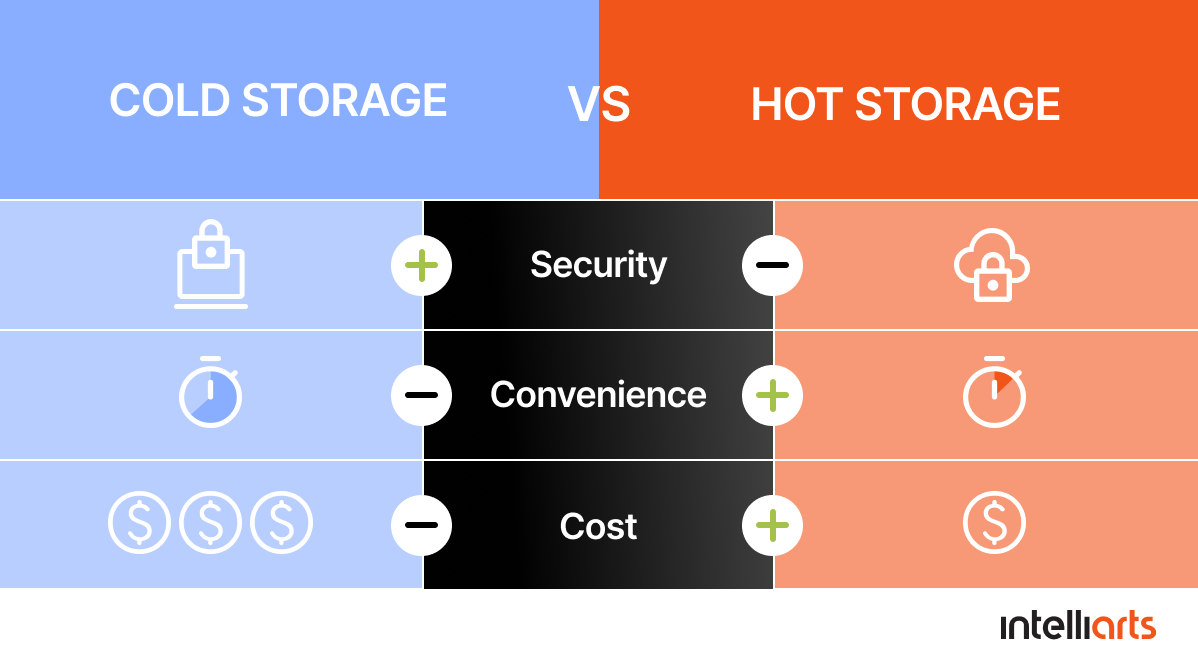
One of the reasons for introducing cold vs. hot storage was to solve the business challenge of data compression. We understood that if we group data more efficiently before uploading it to storage, we’d save place and, thus, the company could cut costs.
Data transformation
Another problem we faced was the inefficient data processing pipeline using Java Hadoop and Cascading frameworks. Although the customer’s data processing pipeline was reliable, it was too slow, out-of-date, and required lots of maintenance effort.
The Intelliarts team approached this problem by aiming to be in line with cutting-edge technologies and advocated for using them. Together with the customer, we have gone a long way in digital transformation from one system to another.
So, we have decided to redesign the data pipeline and transfer services to Spark. We also started using the Databricks hosting service in combination with AWS and Amazon EMR, as well as Scala and Python jobs. This replacement of Java Hadoop and Cascading has added to the speed, ease of use, and efficiency of the data pipeline. (Read more about the benefits of the key three technologies that we introduced below.)

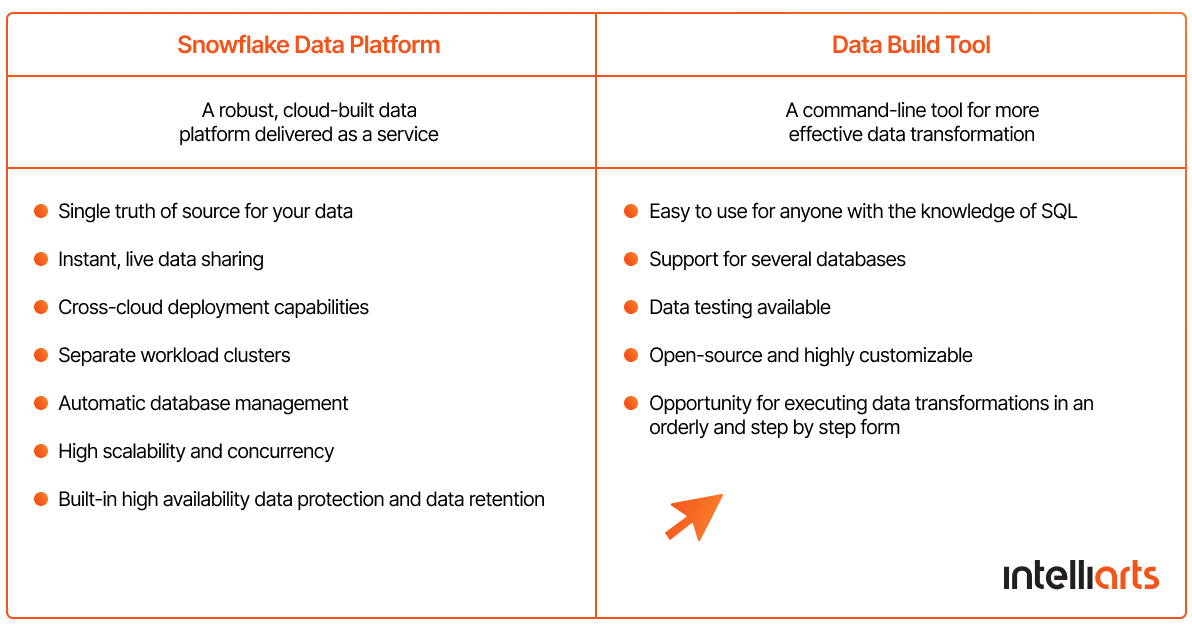
After a few years, since we always aimed at following the industry standard, the Intelliarts team replaced Databricks and Spark with Snowflake, DBT (Data Build Tool), and AWAA (Amazon Managed Workflows for Apache AirFlow). The idea was to substitute ETL processes with ELT and lighter cloud solutions, such as Snowflake. (The table below stresses the major benefits of why we chose different technologies for data transformation.)
DevOps
An important milestone in our project was the use of Terraform, which increased DevOps Maturity in the project. Together with the use of the cloud provisioning tool Ansible, these improvements allowed us to automate building and provisioning of the infrastructure and, thus, make it more reliable.
If we sum up all the improvements Intelliarts made for the infrastructure, we can mention:
-
Increased reliability and reduced human factor at the expense of using Terraform and Ansible. The project was characterized by a large-scale and complex infrastructure, which created the risk of security and the human factor. We solved this problem with a more reliable approach.
-
24/7 support. The Intelliarts team has added automatic notifications. We have also introduced efficient monitoring, which allowed us to track the overall trends. The team became able to provide almost real-time assistance whenever they notice anything wrong like the decline in traffic.
-
Multi-region infrastructure which helped the business provide their services to the end users faster and maintain consistency of workloads.
Security
Together with the customer, we put lots of effort into enhancing the security of the big data solution we’ve built. We’ve secured the business in terms of data leakage. Also, we supported the implementation of GDPR, PII detection, and sensitive data removal. The team introduced data cleaning and other measures that could help the customer protect sensitive data on their part.
Value-added products
At some moment, the Intelliarts team has moved from solving engineering problems only to product challenges. Having volumes of clickstream data, we offered the customer to produce spin-off products, which allowed DDMR to expand its market share. For example, we performed data augmentation for clickstream data by mapping domains to public company stock tickers. As a result, the company received a great value proposition for fintech companies, which were looking for this type of data as an extra source for their analytics.
Value
The project is still in progress, and together with the DDMR partner, we constantly improve the solution and add value to the end-users. During our cooperation, the customer multiplied its annual revenue a few times and won a base of loyal customers. To understand our success in this project, we have grown from zero to operating clusters with 2000 cores and 3700 GB of RAM. The company continues to grow and develop, and Intelliarts is doing its best to contribute to its success by improving the solution.
Among the contributions we made to this project, we can also distinguish between:
-
Building an end-to-end data pipeline, with efficient data collection, storage, processing, and delivery.
-
Being ahead of all technology trends so it led to greater efficiency, speed, and ease of use of the big data solution we’ve built. For DDMR, it also meant better productivity and optimized processes.
-
Looking for any opportunities from the technology perspective to improve efficiency, such as introducing 24/7 support, which allowed the company to provide a better customer experience to its end users.
-
Increasing end-user satisfaction — over the years, the general approach to customer service was formed in a way that we never waited until the end user came to us with a challenge. Instead, the Intelliarts team tried to act on the lead. Whenever we saw the user didn’t access the data for some time, we reached out to them and asked whether any assistance was needed.
-
Providing the company with value-added products, which benefited DDMR with new markets.
Over these seven years, the Intelliarts team has taken charge of the development of the company’s solution, helping DDMR with:
-
Designing and building the ETL/ELT data pipelines
-
Data ingestion and processing
-
Data collection and acquisition
-
Data transformation
-
Optimization of the data delivery systems, including the implementation of batch processing and data streaming technologies
Conclusion
Developing a data pipeline is not an easy task, and many companies find it difficult to build a full-cycle big data solution in-house. Over the years, Intelliarts has gained this expertise and can deliver your business a reliable end-to-end data pipeline or provide a big data consultation. We’ll support you on every step of your data journey and help you use the potential of your big data to boost your business competitiveness.
By integrating Intelliarts’ expertise in building comprehensive data pipelines, your business can also optimize lead scoring, enhancing your ability to prioritize and engage with the most promising prospects effectively.
Planning to build a data pipeline from scratch? Or maybe would like to optimize your existing big data solution? Reach out to Intelliarts to discuss your project with our expert team.







