
Have you known that traffic demand prediction can be achieved with the help of detecting anomalies for 4G networks? Advancements in machine learning and artificial intelligence today allow to optimize 4G networks and, thus, prevent congestion, reduce latency, and ensure balanced and efficient use of network resources.
In this article, software engineering company Intelliarts talks about one particular use case of traffic prediction and describes our research on how to detect anomalies for 4G network optimization with the use of machine learning technology.

Improving 4G networks traffic distribution with the anomaly telecom detection
Previous generations of cellular networks are not very efficient with the distribution of network resources, providing coverage evenly for all territories all the time. As an example, you can envision a massive area with big cities, little towns, or forests that span for miles. All these areas are receiving the same amount of coverage, while cities and towns need more internet traffic, and forests require very little.
Given the high volume of traffic in today’s 4G networks, optimizing the use of frequency resources will help cellular providers achieve impressive energy savings and improve customer service.
Anomaly detection in networks using machine learning allows predicting the traffic demand in various parts of the network, helping operators to distribute it more properly. This article is based on our analysis of the information from the public domain and implementing AI network optimization to effectively solve this problem with one of the possible approaches.
There are multiple solutions for this particular problem, the most interesting include:
- Anomaly detection and classification in cellular networks using automatic labeling technique for applying supervised learning suitable for 2G/3G/4G/5G networks.
- CellPAD, a unified performance network anomaly detection framework for detecting performance anomalies in cellular networks via regression analysis.
Challenges of ML-based telecom anomaly detection
Before we move to the problem solution itself, let’s briefly outline the challenges of ML-based anomaly detection that data scientists usually face:

- Data quality: Since ML models are data-driven, data scientists should care a lot about the quality of the underlying datasets. Avoid null, duplicate, or incomplete data, as well as inconsistency of data formats.
- Data quantity: For better accuracy, you’d better have large training and testing datasets. Anomalies will skew the baseline, but this could be solved with large datasets.
- Choice of the algorithm: There are different anomaly detection algorithms, and data scientists might need to test a few or take a hybrid approach before choosing the most appropriate one. A good starting point is to consider the nature and characteristics of the dataset.
- Degree to which a point becomes an anomaly: In the field, it happens that some objects are more intense anomalies as compared to others. That’s why we have a concept of anomaly or outlier score that implies assessments of the degree to which an object is anomalous.
Now we’ll describe a particular case discussing anomaly detection for 4G networks using AI for network optimization.
Data overview
The research was made with the information extracted from the actual LTE Network. The dataset included 14 features in total, with 12 numerical and 2 categorical. We had almost 40,000 rows of data records with no missing values (empty rows). The team of data analytics divided the information into two labeled classes:
-
Normal or 0: the data doesn’t need any reconfiguration or redistribution
-
Unusual or 1: where the reconfiguration is required due to abnormal activities
The labeling was executed manually based on the amount of traffic in particular parts of the network. However, there is an option for automated data labeling leveraging neural networks. Look up Amazon SageMaker Ground Truth for this function or Data Labeling service from Google’s AI platform.
Data analysis results
Analysis of the labeled data showed us that the whole dataset was imbalanced. We had 26,271 normal (class 0) and 10,183 (class 1) unusual values:

According to the dataset, a Pearson correlation matrix was built:

As you can see, the large number of features are heavily correlated. This correlation allows us to understand how different attributes in the dataset are connected to each other. It serves as a basic quantity for different modeling techniques, and sometimes can help us to discover a casual relationship and predict one attribute based on the other.
This time we have perfectly positive and negative attributes, which may lead to the multicollinearity problem that will impact the performance of a model in a bad way. It happens when one predictor variable in a multi-regression model could be predicted linearly from any other variables highly accurately.
Lucky for us, decision trees and boosted trees are able to solve this issue by picking a single perfectly correlated feature at the moment of splitting. When deciding to use other models like Logistic Regression or Linear Regression, keep in mind that they can experience this problem and need extra adjustment before training. Among other methods to deal with multicollinearity are Principle Component Analysis (PCA) and the deletion of perfectly correlated features. The best option for us was the usage of tree-based algorithms because they don’t need any adjustments to deal with this problem.
Basic accuracy is one of the key metrics to measure classification, and it is the ratio of correct predictions to the total number of samples in the dataset. As was mentioned previously, we have imbalanced classes in our case, which means that basic accuracy can provide us with not correct results due to high metrics that don’t show the prediction capacity for the minority class.
We can have accuracy close to 100%, but still have low prediction capacity in a particular class because anomalies are the rarest in the dataset. Instead of accuracy, we decided to use the F1 metric, a harmonic average of precision and recall, which is great for imbalanced classification situations. F1 metrics cover the range from 0 to 1, where 0 is a total failure and 1 is a perfect classification.
The samples can be sorted in four ways:
-
True Positive, TP — a positive label and a positive classification
-
True Negative, TN — a negative label and a negative classification
-
False Positive, FP — a negative label and a positive classification
-
False Negative, FN — a positive label and a negative classification
Here is how the metrics of the imbalanced classes look like:
True Positive Rate, Recall, or Sensitivity
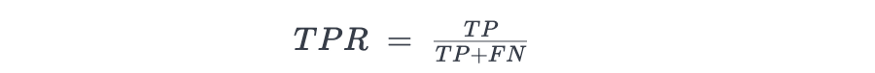
False Positive Rate or Fall-out

Precision

True Negative Rate or Specificity

The formula of the F1-score metric is:

Algorithms of our choice
DecisionTreeClassifier was a great place to begin for us, as we go 94% accuracy on the test selection without any additional tweaks. To make our results even better, we moved to BaggingClassifier, also a tree algorithm that provided us with 96% accuracy according to the F1-score metric. We also tried RandomForestClassifier and GradientBoostingClassifier algorithms, which gave us 91% and 93% accuracy.
Feature engineering step
We achieved great results thanks to tree-based algorithms, but there was still some room to grow, so we decided to improve the accuracy further. While processing data, we added time features (minutes and hours), added the possibility to extract the part of the day from the “time” parameter, and tried the time lags feature—these moves didn’t help much. However, what did help to improve the outcomes of the model was the usage of upsampling techniques that allowed feature transformation and balancing the data.
Parameters tuning step
All out-of-the-box algorithms showed results that exceeded 90%, which was great, but with the GridSearch technique, it was possible to improve them even further. Among four algorithms, GridSearch was the most effective for GradientBoostingClassifier and helped to achieve an astonishing 99% accuracy to complete our initial goal.
Conclusion
The issue we highlighted in this article is very common among all mobile internet providers that offer 3G or 4G coverage and can be dealt with to improve the experience of users. In this scenario, the “anomaly” is seen as a waste of internet traffic. Network anomaly detection using machine learning can make a decision on the effectiveness of the resource distribution based on input data. The described usage of a Gradient Boosting Classifier tuned with Grid Search can help companies to evaluate the efficiency of traffic distribution and advise them which parameters need to be changed in order to provide the best user experience.
Ineffective traffic utilization is not the only problem that Data Science can solve in the telecom industry. Solutions like fraud detection, predictive analytics, customer segmentation, churn prevention, lifetime value prediction, and object detection with ML are also possible with the right team of developers. While implementing a robust automatic data extraction solution can significantly streamline data processing, enhancing overall operational efficiency in various sectors.
We at Intelliarts love to help companies to solve the challenges with data strategy design and implementation, so if you have any questions related to building ML pipelines properly or other areas of Data Science — feel free to reach out.

FAQ
1. How do I optimize my 4G network?
The most efficient strategies for 4G network optimization include proper placement of antennas, regular updates of firmware, implementation of Quality of Service (QoS) policies to prioritize critical data traffic, interference management, etc.
2. What is network optimization?
Network optimization refers to fine-tuning and enhancing a computer or telecommunication network to improve its performance, efficiency, and overall functionality.
3. Can you use machine learning for network optimization?
Sure. As we proved above, machine learning is a great way for network optimization. By analyzing large datasets, ML algorithms can identify patterns, predict potential problems, and dynamically adjust network parameters for better network performance.
4. What types of anomalies can be detected using ML in 4G networks?
Here we’re speaking about three types of anomalies: anomalous outliers, anomalous cycles, and anomalous collections.
5. Is ML-based anomaly detection suitable for small 4G network operators as well?
Building an ML model can take some time and resources, so small 4G network operators should estimate ROI attentively before investing in such initiatives.
6. Can telecom companies improve network performance with AI?
Absolutely. Leveraging AI, particularly machine learning algorithms, is instrumental in enhancing network performance. By analyzing extensive datasets, AI algorithms can discern patterns, anticipate issues, and adapt network parameters dynamically for optimal performance.








