
In two of our previous articles, Predictive Maintenance Part 1: The Domain Overview and Predictive Maintenance Part 2: Machine Learning techniques, to solve maintenance problem, we explained the basics of Predictive Maintenance and how to solve this problem using three traditional machine learning techniques. If you missed it, we highly recommend catching up because this time we will break down the more sophisticated way to solve the solve problem — Predictive maintenance using deep learning.
The difference between machine learning and deep learning
As we mentioned in the previous article, machine learning is the science of teaching computers to act and learn from experience without being explicitly programmed. Machine learning is widely used for various tasks, including fraud detection, prediction of equipment failures, autonomous vehicles, and more.
Deep learning can be considered a subset of machine learning; however, its capabilities and business implementations are different. The key differences between predictive maintenance and machine learning include:
-
Deep learning requires larger datasets for training, takes a much longer time to train, and trains on GPU (not CPU), compared to machine learning. While for machine learning thousands of data points are required, deep learning needs millions.
-
Classical machine learning has a limited capability for hyper-parameter tuning, while deep learning can be tuned in various ways.
-
As an output, deep learning can provide anything from numerical values to free-form elements, such as free text and sounds. Machine learning, on the other hand, provides numerical value like classification or score.
-
Deep learning algorithms are largely self-directed once they are put into production. Machine learning algorithms are directed by data analysts to examine specific variables in a dataset.
Deep Learning Techniques for Predictive Maintenance Solutions
Auto-Encoder
The first deep learning technique to be discussed is Auto-Encoder. This a type of unsupervised artificial neural network. Auto-Encoder learns how to compress and encode data effectively and, after that, learns how to reconstruct data back from a reduced encoded representation to a form as close to the original as possible. Auto-Encoder is built to reduce data dimension by figuring out how to reduce the noise in the data. Here is a picture to illustrate how it works:

Auto-Encoder comprises four main parts: Encoder, Bottleneck, Decoder, and Reconstruction Loss. The training is all about minimizing Reconstruction Loss of the network by using backpropagation. Among popular usages of Auto-Encoders are anomaly detection and image recognition.

Use Case of Deep Learning: Remaining Useful Life (RUL) Prediction of Bearings
One of the key reasons for failures in industrial machinery is the degradation of bearings. Having a correct prediction for degradation is crucial for introducing the best maintenance strategy, which will help manufacturers lower overall costs and eliminate unwanted downtime or even casualties. There is an Auto-Encoder-based solution for RUL prediction of bearings.
Human experts usually base approaches for RUL prediction on manual feature extraction and selection. However, it is possible to leverage a groundbreaking two-stage automated approach using Deep Neural Networks (DNNs) to estimate the RUL of bearings.
First, it’s recommended to implement a denoising Auto-Encoder-based DNN to classify acquired signals of the target bearings into multiple degradation phases. The representative features are received directly from the raw signal after the training process of the Deep Neural Network.
Second, based on shallow neural networks, the regression models can be developed for each separate degradation phase.
The resulting remaining useful life is calculated by smoothing regression results from multiple models. This approach already showed satisfactory performance and delivered precise predictions for real-life bearing degradation datasets during different operating conditions.
Recurrent Neural Network
Another Deep Learning technique is Recurrent Neural Network (RNN) is a class of artificial neural networks where the connections between units form a directed graph along a sequence. This factor enables RNN to exhibit dynamic temporal behavior for a time sequence. RNNs can use their internal memory to process sequences of inputs, which is impossible for feed-forward neural networks. That’s why they are perfect for such challenging tasks as speech recognition or unsegmented, connected handwriting.
When your model needs a context to generate an output based on input, a Recurrent Neural Network can solve this challenge. Sometimes, the context is a deciding factor in the correct output of the model.
To make an analogy, let’s say you read the book and the whole time through you have the context because you remembered all the events from the very beginning, and you can relate to events correctly. Just like that, Recurrent Neural Network remembers events in context, unlike other neural networks, in which inputs are being processed independently of each other.
If we look at the text recognition example, RNN remembers the relation among words in a given sentence to achieve better results in predicting a missing word. This understanding by RNN is achieved during the training process and is possible because of the creation of smaller networks with loops in them:
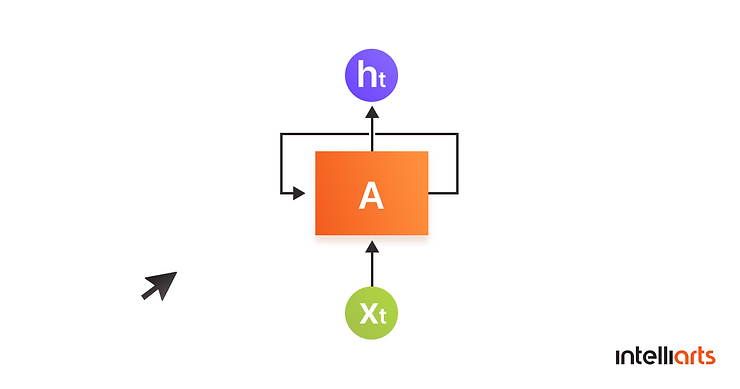
This is how the loop structure looks. Thanks to this structure, the neural network is able to process a sequence of inputs.

The network takes the x(0) and outputs h(0), which combined with x(1) is the input for the next step. After that, the same principle repeats as many times as needed. As illustrated, a Recurrent Neural Network works by remembering context from the previous output.

Use Case of Deep Learning: Predictive Maintenance of Mill Fan Systems
There is a solution that allows for predicting the amplitude of vibration for a mill fan system. In the case study, successful results were achieved thanks to monitoring the vibration of the rotor bearing block located the closest to the mill. The observation lasted for an entire calendar year, with the replacement of the rotor of the mill fan happening in the first month. The rotor worked after the replacement for nearly 380 hours. Having the data before and after the replacement, the experts concluded that the new rotor has higher amplitudes compared to the old one.
So, based on preliminary analysis of sensor data the nearest to the mill rotor bearing block, it was decided to build a nonlinear model that would enable the timely prediction of vibrations tendencies that would signal on system breaking down. The expert team used two types of Recurrent Neural Networks in a comparison. The first one was historical Elman architecture, and the second one was the newly developed type of RNN called Echo state networks (ESN).
Early analysis by the expert team showed the advantages of ESN over the Elman network. In fact, Normalized Root-Mean-Square Error (NRMSE) for Elman architecture equaled 0.52 on a training set and 0.69 on a testing set. The total training time took over 5 hours. For ESN architecture, however, NRMSE on a training set was 0.48 and 0.68 on a testing set, with a total training time of around 10 minutes. The obtained results demonstrated that ESN architecture works better in terms of accuracy and training time. With this approach, we can effectively predict the amplitude of vibration for a mill fan system.
LSTM Networks
This is an expansion of the idea of a Recurrent Neural Network. Long Short Term Memory networks (LSTMs) are a type of RNN that can learn long-term dependencies. Hochreiter & Schmidhuber introduced this concept in 1997, and since then many other experts have popularized and improved it.
LSTM networks have proven to be great in solving a lot of complex challenges in areas like speech recognition, time series prediction, robot control, market prediction, and others. They are built to remember information for long periods by design.
Recurrent Neural Networks, as we covered above, look like a chain of repeating modules. Standard RNNs have a simple structure with a single tanh layer:
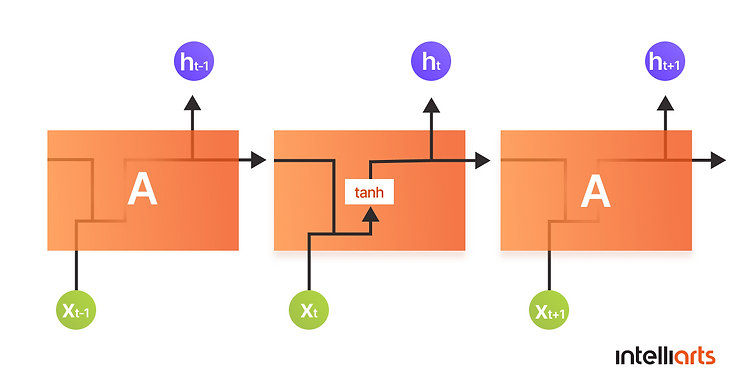
LSTMs structure is also chain-like, but each repeating module has four neural network layers instead of one:

This is what the notation inside a module means:
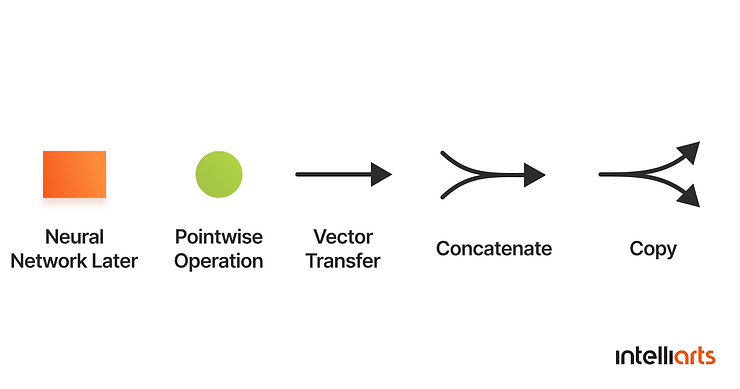
Each line carries an entire vector from the output of one node to the input of others. Pink circles stand for pointwise operations, while yellow boxes include learned neural network layers. The merging line denotes concatenation, and a forking line denotes its content being copied, and the copies are transferred to different locations.
The main idea behind LSTMs is the cell state. As you see, the horizontal line (the cell state) is running through each module at the top of the diagram. It runs through an entire chain with minor interactions, making the information flow along the entire chain easily while staying unchanged:

The LSTM can remove from or add information to the cell state, which is regulated by structures called “gates”:

Use Case of Deep Learning: Predict the current state of an engine
LSTMs can be efficient in estimating the degradation level of engines. And here is one of the case studies on this.
Before building a model, the following equation for percentage residual life of engine was used:
R(t) = (Time to failure – Current Age) / Time to failure
When R(t) equals one, it shows that the remaining life of an engine is at 100% point. When R(t) equals zero, it means that the engine has broken down and its remaining life is at 0%. The values of R(t) were divided into the following classes to indicate the life conditions of the components:
-
Healthy – the engine is at the very beginning of its lifetime
-
Caution – the engine is operating intensively and needs to be taken care of. Action is needed to avoid the Repair state
-
Repair – the engine needs repair
-
Failure – this is the most unwanted state that leads to a breakdown
The solution was to set up an alert mechanism before a component moves from Caution to a Repair condition. This solution would allow fixing or replacing the component, avoiding the stoppage of the system.
LSTM algorithm was implemented to build an efficient remaining life of an engine prediction model. After performing preliminary calculations and data analysis, the following feature selection process took place:
-
The total temperature at fan inlet (°R), pressure at fan inlet (psia), demanded fan speed (rpm), demanded corrected fan speed (rpm) sensor measurements were dropped from the input because of having zero variance.
-
The total temperature at HPC outlet (°R), total temperature at LPT outlet (°R), total pressure in bypass-duct (psia), total pressure at HPC outlet (psia), ratio of fuel flow to Ps30 (pps/psi), bleed enthalpy, HPT coolant bleed (lbm/s) sensor measurements were dropped due to the high correlation with other sensors.
-
The remaining sensor measurements were used as input variables: the total temperature at LPC outlet (°R), physical fan speed (rpm), physical core speed (rpm), engine pressure ratio (P50/P2), engine pressure ratio (P50/P2), corrected fan speed (rpm), corrected core speed (rpm), bypass ratio, burner fuel-air ratio, LPT coolant bleed (lbm/s).
After training the LSTM model on selected inputs, the resulting model was able to achieve an impressive 85% training accuracy of RUL prediction.
The Advantages and Disadvantages of Mentioned Deep Learning Algorithms
Predictive maintenance using deep learning may be tricky when you come to choosing the right algorithm. Each technique suits one case better than the other and has its own strong and weak points. See the advantages and disadvantages of ML-based deep learning in the table below.

Conclusion
We covered three deep learning-based techniques that can solve a Predictive Maintenance problem. It is impossible to name the sole best technique because each unique case requires an individual approach. Experts in ML-based deep learning know what algorithm to choose based on their experience and a specific business domain.
While all three deep learning techniques mentioned in this article can become a powerful solution to maintenance problems, they still have some major challenges. The biggest ones are probably the amount of data you need to have for a deep learning solution to work properly and the amount of computing power. Incorporating automatic data extraction from PDF can significantly streamline data processing, enhancing the accuracy and speed of analytical tasks.
Sometimes, a less powerful machine learning algorithm can be much more efficient and cost-effective for your Predictive Maintenance project. In any scenario, it makes sense to contact experts in machine learning and deep learning for proper evaluation of your situation that will help with actionable strategies to improve your processes.
We at Intelliarts AI love to help companies to solve challenges with data strategy design and implementation, so if you have questions related to Predictive Maintenance in particular or other areas of Machine Learning — feel free to reach out.

FAQ
1. Top Machine Learning Techniques for Predictive Maintenance
The choice of an ML algorithm totally depends on the model results it provides. Among those most commonly used for predictive maintenance, there are traditional ML techniques, such as a decision tree, k-Nearest Neighbor (KNN) algorithm, the Support Vector Machines (SVM), and the K-Means algorithm. Also, data scientists may choose deep learning techniques, for example, auto-encoder, a recurrent neural network (RNN), or long short term memory (LSTM).
2. How do you improve maintenance with deep learning?
Deep learning algorithms are largely self-directed when they are put into production. Hence, a predictive maintenance solution built based on deep learning algorithms will need as little human intervention as possible.
3. How to implement Machine Learning for Predictive Maintenance?
Implementing machine learning for predictive maintenance requires standard steps in building an ML model. A manufacturer starts with data collection from IoT sensors. Then, the company prepares the dataset for further processing by cleaning the data and visualizing it. The next step is to choose the ML algorithm(s), feed it with the data, and evaluate the model. After parameter tuning, the ML model is deployed and integrated into the manufacturer’s system. Ideally, data scientists help to monitor the results and maintain the ML model for better performance.







