
We continue our series of articles about predictive maintenance. In previous articles, we’ve discussed:
The difference between reactive maintenance, preventive maintenance, and predictive maintenance in part 1
- How machine learning techniques can solve a maintenance problem in part 2
- How deep learning can solve maintenance challenges for the organization in part 3
This time, we will talk about our own case study, in which we provided a solution for the preventive maintenance of hydraulic systems.
What are hydraulic systems?
Predictive maintenance for hydraulics is a crucial approach to ensuring the efficient operation of hydraulic systems. While the usage of a particular hydraulic system may differ, they all operate under the same concept. Simply put, hydraulic systems function by using pressurized fluid to perform tasks. Imagine pressure being applied to a contained fluid at any point and getting transmitted undiminished. The pressurized fluid creates a force or power by acting upon every part of the section containing a vessel. This is what the basic hydraulic system looks like:

This method of transitioning power can be controlled accurately, easily, and considerably quieter compared to other methods.
There are two main types of hydraulic systems: open-loop and closed-loop. In an open-loop system, the new fluid enters the pump from the reservoir, and the fluid from the actuator is passed into the reservoir. In a closed-loop system, the fluid passes continuously between the actuator and pump without entering the reservoir.
You may find examples of these systems in the industries like automotive, aviation, manufacturing, marine, construction, robotics, and more. The most popular applications of hydraulic systems include lifts, brakes, steering, jacks, heavy machinery, components for airplanes and helicopters, and shock absorbers.
What are the benefits of proper maintenance of hydraulic systems?
Cost reduction is the biggest advantage of having a proper predictive maintenance strategy for your hydraulic system. This can result from other benefits, including improved productivity, safety, reduced maintenance costs, and lowered probability of unexpected downtime.
The challenge of our customer that we were asked to solve
No company is saved from human error, for example, in detecting faults or monitoring the statuses of separate components in hydraulic systems. This creates a major problem for business owners because malfunctioning of a single component like a broken pump can disrupt an entire hydraulic system.

Our client, who was aware of this fact, reached out to us regarding the hydraulic system maintenance. The company wanted to implement a machine learning-based system which could predict the degradation level of specific components. The components included a cooler, valve, pump, and hydraulic accumulator.
Our customer had a complex hydraulic system with a primary working and secondary cooling-filtration circuit; both circuits were connected via the oil tank. The expert team on the customer’s side had already gathered a dataset with labeled degradation levels for each separate component. We had a goal of building a machine learning system that could predict accurately the correct state of degradation for the previously mentioned components of the system.
Dataset overview
We had a raw dataset provided by the customer based on records of many physical and virtual sensors. These sensors were installed on the aforementioned components: cooler, valve, pump, and hydraulic accumulator.
Physical sensors are used for measuring parameters during the load cycle of the hydraulic system (i.e. the time interval between consecutive commencement of application of external load). Meanwhile, virtual sensors use heterogeneous physical sensors to combine types of data to compute a measurement. Finally, heterogeneous physical sensors are used in diagnostics to generate information to get the observed synergistic effects. These are nonlinear cumulative effects of two active ingredients with similar or related outcomes of their different activities or active ingredients with sequential or supplemental activities.
So, we had records of 17 sensors in our dataset. Those records included information on 2205 full load cycles of the hydraulic system, with 60 seconds duration each. Luckily for us, the dataset had no missing values, which would help us build a more precise machine learning solution.
Let’s break down what sensors, which provided input to our dataset, were measuring:
-
For pressure, six physical sensors were used, which were measuring in bars at 100 Hz frequency
-
For motor power, one physical sensor was used, which was measuring in W at 100 Hz frequency
-
The flow rate was measured by two physical sensors in l/min (liters per minute) at a 10 Hz frequency
-
The temperature parameter was measured by four physical sensors in °C at 1 Hz frequency
-
The vibration was measured in mm/s by one physical sensor at a 1 Hz frequency
-
Both cooling efficiency and the system efficiency were measured by two separate virtual sensors respectively in % at 1 Hz frequency
-
Finally, cooling power was measured in kW at 1 Hz frequency with one virtual sensor
The total number of features was a massive 43 680.
As the goal was to predict degradation levels for specific components, the customer’s expert team has already made definitions of degradation for each load cycle, and we had that information in our initial dataset. Here is a quick overview of what types of degradation we had for each component of the hydraulic system:
-
The cooler condition was divided into three degradation levels: 3% – close to a total failure, 20% – reduced efficiency, and 100% – full efficiency
-
The valve condition was divided into four degradation levels: 73% – close to total failure, 80% – severe lag, 90% – small lag, 100% – optimal switching behavior
-
The internal pump leakage was divided into three degradation levels: 2 – severe leakage, 1 – weak leakage, 0 – no leakage
-
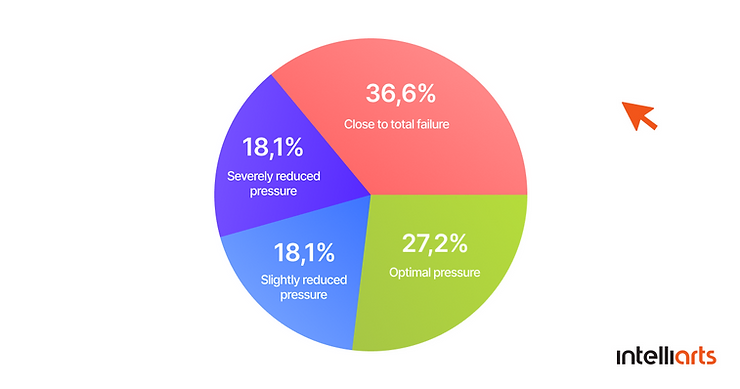
The hydraulic accumulator was divided into four degradation levels: 90 bar – close to total failure, 100 bar – severely reduced pressure, 115 bar – slightly reduced pressure, 130 bar – optimal pressure
Based on this data, we made the conclusion that cooler condition, valve condition, internal pump leakage, and hydraulic accumulator prediction are multiclass classification problems.

Feature engineering
Having such a huge number of features in the system (43 680) has its own nuances in building a machine learning model. This amount of features may lead to overfitting. On training data, overfitting would lead to some great results. However, with the real-life production data, the good performance of the overfitted model is highly unlikely.
Taking this factor into account, we have decided to make a representation of each sensor’s measurements per load cycle using mean, min, max, median, the position of maximum value, variance, skewness, and kurtosis. This allowed us to make a representation of signal shape and distribution of density characteristics. We recognized those features as ones that represented component state per load cycle. Putting this idea into practice helped us reduce the number of features from an enormous 43 680 into a much more tangible and easier to analyze 136 features. Additionally, we used different combinations of those features for each task.
Data Analysis
The dataset of valve condition labels can be considered unbalanced, with 51% records with optimal switching behavior, 16% – small lag, 16% – severe lag, and 16% – close to total failure.

The cooler condition dataset was highly balanced:

In the internal pump leakage, the “no leakage” value prevails over “weak leakage” and “severe leakage”:

The dataset for the hydraulic accumulator, however, is far more balanced compared to internal pump leakage and valve condition: 90 – 36%, 130 – 27%, 115 – 18%, 100 – 18%.
Also, after exploratory analysis, we concluded that a lot of sensors are highly correlated. This is a significant factor that may lead to a multicollinearity problem. We explained what this problem is and how to deal with it using various approaches in How ML-Based Anomaly Detection can improve the performance of 4G networks.
Modeling
Let’s go through four machine learning models we developed for degradation level prediction of components of our hydraulic system.
1. Cooler condition prediction
To represent measurements per load cycle for each sensor, we used median, the position of maximum value, variance, skewness, and kurtosis. The experiments with tree-based algorithms showed the outcome was highly dependent on virtual sensors that represent cooler efficiency. So, we decided to drop virtual sensors since it can mean that virtual sensors bring data leakage. And it’s not a robust way to make a model prediction highly dependent only on a small specific group of sensors.

To train the algorithm, we used 80% of the data, and for testing we took 20%. The best algorithm we leveraged to get the highest results for this component was the XGBoost classifier with tuned parameters: min_child_weight=0.02, eta=0.006, n_estimators=1000. For cross-validation, we chose the StratifiedKFold method with 6 splits. We achieved a 0.998 average accuracy parameter on the test sets.
2. Valve condition prediction
To represent each sensor’s measurement per load cycle, we used the position of maximum value, variance, skewness, and kurtosis. We decided to drop all features that correlated with target values less than 0.15. Once again, we trained the algorithm using 80% of the data and tested it using 20%.
The final pipeline we solved the problem with looked like this:
-
We started with implementing Independent Component Analysis using FastICA algorithm with tol=0.8500000000000001
-
The next step was to standardize features by removing the mean and scaling to unit variance using the StandardScaler algorithm
-
As the last step, we implemented RandomForestClassifier with parameters bootstrap=False, criterion=”entropy”, max_features=0.45, min_samples_leaf=2, min_samples_split=2, n_estimators=2000, class_weight=”balanced”
Just like with Cooler condition prediction, the StratifiedKFold method with 6 splits was used as a cross-validation algorithm. We achieved average accuracy on test sets as high as 0.998.
3. Internal pump leakage prediction
To represent each sensor’s measurement per load cycle in the model, we used mean, min, max, median, the position of maximum value, variance, skewness, and kurtosis. 80% of the data was used for training the algorithm and 20% for testing. We found out that, for this component, the best algorithm was RandomForestClassifier. After the cross-validation with the StratifiedKFold method with 6 splits, the average accuracy parameter was 0.996.
4. Hydraulic accumulator prediction
We took the data on mean, min, max, median, the position of maximum value, variance, skewness, and kurtosis, as a representation of each sensor’s measurements per load cycle. Just like in the previous three cases, 80% of the data was used for algorithm training and 20% for testing. The best algorithm for building a solution for this component has proven to be XGBoost classifier with tuned parameters: min_child_weight=0.01, eta=0.09, n_estimators=3000. After the cross-validation of the algorithm using the StratifiedKFold method with 6 splits, we saw a 0.990 average accuracy on the test sets.
How to implement predictive maintenance in hydraulic systems with machine learning

The implementation of ML-based predictive maintenance into a hydraulic system is very much like building any other ML-powered system. Here is your plan to follow:
- Define your goals and objectives. You need a clear understanding of your project goals, timeline, and budget. Make these goals measurable and translate them into a detailed roadmap. A good idea is to monitor the progress of your project based on these goals.
- Get a professional team on board. Your team of IT professionals should work side by side with the operators on the factory floor and the management of the manufacturing facility. Also, don’t forget to build ML expertise to implement an ML-powered solution successfully.
- Start with a pilot project. Following the “less-is-better” principle will help you not to waste your company’s resources. Choose one or two most critical assets in the hydraulic system and build your PdM solution. This way, you find out any potential problems before scaling up.
- Set up data collection. Identify the data your company is sitting on and the data gaps you have to bridge. By enlisting the help of data scientists, also decide on how you’re going to collect and store your data.
- Choose algorithms. Based on the collected data, you have to build machine learning models that would help you predict the equipment state in the hydraulic system. Choose the right algorithms for your solution, feed the model with data, evaluate the results, and fine-tune the model. Also, make sure you integrate the ML solution into the hydraulic system efficiently.
- Improve the solution. Strive for continuous improvement with your model results. Make sure you adjust your solution whenever you see significant changes in data or performance drops.
Conclusion
Our customer was completely satisfied with the results. The initial expectation was to achieve accuracy above 95% for each machine learning model, and with the developed solution we successfully completed this goal.
After data collecting, data analysis, modeling, and deploying four models responsible for monitoring specific components of the hydraulic system, we also developed API endpoints triggered after each load cycle of the system. When any model returns a label indicating the inefficient performance of the system, the maintenance experts get immediate notification regarding the problem. So the experts know exactly which component of the hydraulic system requires their attention at the moment.
Our success in this project underscores the critical role that software engineering services played in developing and integrating the predictive maintenance solution.
Our team continues to monitor the performance of models and is ready to retrain them on demand. There are a few reasons data science models need to be retrained, which include:
-
new sensors added to the system
-
new settings of the system
-
the changes in the elements of the system
The hydraulic systems problems and challenges described in this case study are quite common. If you have enough meaningful data, consider the development of a machine learning solution that easily pinpoints a problem and ultimately saves your money and equipment in the organization.
Data engineers and ML engineers at Intelliarts would be happy to help you build a proper data collection pipeline, collect the necessary data, and build ML-based predictive maintenance for hydraulics or any other valuable assets in your system. You can also learn more about data collection for a machine-learning project.
We at Intelliarts love to help companies solve challenges with data strategy design and implementation, so if you have questions related to predictive maintenance for fluid power systems or other areas of machine learning — feel free to reach out.

FAQ
-
What type of data is required for ML-based predictive maintenance in hydraulics?
A manufacturer needs all sorts of historical and real-time data they could collect from physical and virtual sensors connected to equipment and its parts. This data could include but is not limited to load cycles of the hydraulic system, flow rate, temperature parameters, vibration patterns, cooling efficiency, cooling power, system efficiency, motor power, etc.
-
Can predictive maintenance with ML be applied to all types of hydraulic systems?
Ml-powered predictive maintenance could be applied to all types of hydraulic systems where a manufacturer has a chance to monitor an asset’s state and status.
-
How does predictive maintenance enhance the performance of hydraulic systems?
Predictive maintenance helps you detect any potential equipment failures in the hydraulic system before they actually occur. So, the manufacturer could reduce downtime to a minimum and improve performance in the long run.







